传家宝级八股文问题:Redis为什么这么快?
简单回答:
1. 基于内存实现
2. 高效的数据结构(动态字符串(SDS)、跳表(skiplist)、哈希表(hashtable)、整数数组(intset)、快速列表(quicklist)、紧凑列表(listpack)、基数树(stream)等等)
3. 单线程结合多线程(避免频繁的上下文切换和资源竞争)
4. I/O多路复用;非阻塞I/O模型
5. 高性能的自定义通讯协议RESP
接下来展开说说
低延迟高读取速度:以ddr4内存为例,延迟基本在15纳秒左右,优秀的硬件可以做到更低;读写速度基本在30000MB/s以上,而顶级的PCIE4.0 SSD的读取延迟也在15微妙左右,顺序读取速度在7000MB/s左右,从延迟到速度全方位碾压。
CPU大多数场景下不会成为瓶颈:在Redis诞生之初,在只有基础类型的情况下,由于算法的时间复杂度很低,基本都是O(N)或O(log(N)),所以不太会占用太多的CPU资源,反而内存的随机读写性能会成为瓶颈。但现在也有CPU产生瓶颈的情况,例如GEO计算距离;大量数据排序;大量数据合并等操作。
为了追求速度,不同数据类型使用不同的数据结构速度才得以提升,每种数据类型都有一种或者多种数据结构来支撑。
Redis 使用对象(redisObject)来表示数据库中的键值,当我们在 Redis 中创建一个键值对时,至少创建两个对象,一个对象是用做键值对的键对象,另一个是键值对的值对象。
例如我们执行 SET KeyString ValueString 时,键值对的键是一个包含了字符串“KeyString“的对象,键值对的值对象是包含字符串”ValueString”的对象。
redisObject
1 2 3 4 5 6 7 8 9 | struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr; }; |
这个结构可以表示所有基本的 Redis 数据类型,如字符串、列表、集合、有序集合等。
type 字段记录了数据的类型, 定义如下:
1 2 3 4 5 6 7 8 9 | /* The actual Redis Object */ #define OBJ_STRING 0 /* String object. */ #define OBJ_LIST 1 /* List object. */ #define OBJ_SET 2 /* Set object. */ #define OBJ_ZSET 3 /* Sorted set object. */ #define OBJ_HASH 4 /* Hash object. */ #define OBJ_MODULE 5 /* Module object. */ #define OBJ_STREAM 6 /* Stream object. */ |
refcount 字段记录了一个对象在多个位置引用同一个对象而不需要多次分配。
ptr 字段指向对象的实际表示,即使是相同类型的对象,其表示方式也可能因使用的编码而有所不同。
Redis 对象在 Redis 内部广泛使用,但为避免间接访问的开销,在许多地方最近我们只是使用未包装在 Redis 对象内部的普通动态字符串。
encoding字段决定了数据存储的实际类型,源码中的枚举如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | /* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation */ #define OBJ_ENCODING_INT 1 /* Encoded as integer */ #define OBJ_ENCODING_HT 2 /* Encoded as hash table */ #define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */ #define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */ #define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */ #define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */ #define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */ |
String(OBJ_STRING):
存储整型数字的话,采用 int 类型的编码,如果是非数字的话,采用 raw 编码。
List(OBJ_LIST):
List对象的编码使用quicklist实现;需要注意的是,其他八股文中会说List对象的编码可以是linklist和ziplist,但Redis5.0以后,官方逐步使用listpack完全替代了ziplist,quicklist完全替代了linklist,所以本身没有问题,但知识点已经过时。
Hash(OBJ_HASH):
Hash 对象的编码可以是 listpack 或 hashtable(dict)。这里网上的其他材料也会根据配置文件的key list-max-ziplist-entries 512 觉得还在使用ziplist,可是上面的枚举源码中明确写出了no longer used,出于实事求是的目的翻翻源码,终于在源码中找到了答案,配置key虽然没变,但是读取后实际上已经将值读取到了新的key中
1 2 3 4 5 6 7 8 9 10 11 | // config.c line 3193 createSizeTConfig("hash-max-listpack-entries", "hash-max-ziplist-entries", MODIFIABLE_CONFIG, 0, LONG_MAX, server.hash_max_listpack_entries, 512, INTEGER_CONFIG, NULL, NULL), // 新版本redis.conf ############################### ADVANCED CONFIG ############################### # Hashes are encoded using a memory efficient data structure when they have a # small number of entries, and the biggest entry does not exceed a given # threshold. These thresholds can be configured using the following directives. hash-max-listpack-entries 512 hash-max-listpack-value 64 |
rdb.c line 930
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | else if (o->type == OBJ_HASH) { /* Save a hash value */ if (o->encoding == OBJ_ENCODING_LISTPACK) { size_t l = lpBytes((unsigned char*)o->ptr); if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1; nwritten += n; } else if (o->encoding == OBJ_ENCODING_HT) { dictIterator *di = dictGetIterator(o->ptr); dictEntry *de; if ((n = rdbSaveLen(rdb,dictSize((dict*)o->ptr))) == -1) { dictReleaseIterator(di); return -1; } nwritten += n; while((de = dictNext(di)) != NULL) { sds field = dictGetKey(de); sds value = dictGetVal(de); if ((n = rdbSaveRawString(rdb,(unsigned char*)field, sdslen(field))) == -1) { dictReleaseIterator(di); return -1; } nwritten += n; if ((n = rdbSaveRawString(rdb,(unsigned char*)value, sdslen(value))) == -1) { dictReleaseIterator(di); return -1; } nwritten += n; } dictReleaseIterator(di); } else { serverPanic("Unknown hash encoding"); } } |
当 Hash 对象同时满足以下两个条件时,Hash 对象采用 listpack 编码:
Hash 对象保存的所有键值对的键和值的字符串长度均小于 64 字节。
Hash 对象保存的键值对数量小于 512 个。
否则就是 hashtable 编码。
Set(OBJ_SET):
Set 对象的编码可以是 intset 或 hashtable 或listpack,intset 编码的对象使用整数集合作为底层实现,把所有元素都保存在一个整数集合里面。
保存元素为整数且元素个数小于一定范围使用 intset 编码,任意条件不满足,则根据实际情况使用 hashtable 或 listpack 编码;
Zset(OBJ_ZSET):
Zset 对象的编码可以是 listpack 或 zskiplist, 当保存的对象少于128个且单个元素的长度小于64字节时回使用listpack,任一条件不满足是会使用zskiplist进行保存。
接下来详细解释下底层数据结构:
Redis是用C实现的,那说的这么玄乎的SDS(Simple Dynamic String)是个什么新类型吗?答案是不是,直接看源码中的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | typedef char *sds; /* Note: sdshdr5 is never used, we just access the flags byte directly. * However is here to document the layout of type 5 SDS strings. */ struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; #define SDS_TYPE_5 0 #define SDS_TYPE_8 1 #define SDS_TYPE_16 2 #define SDS_TYPE_32 3 #define SDS_TYPE_64 4 |
从源码可以看出,sds其实就是个指针而已。这里定义了5中不同的数据结构,使用一个字节的char类型作为类型标识,低3位存储类型, 高5位预留。
仔细看源码会发现结构体在定义的时候加入了__attribute__ ((__packed__))标识,这个标识的作用就是告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐。
Redis为什么要这么做呢?
这里有个细节,Redis的sds指向的地址实际是结构体中buf[],而不是结构体开头的len的,所有保证了能够跟一些传统string.h中的定义保持一致。
而且如果这里内存不对齐,那么使用使用指针-1即可访问到flags(因为char在不进行内存对其的情况下,肯定在buf[]的前一个地址),从而通过位运算得到具体的结构体类型,字符串长度,已经分配的内存长度等等,一举两得。
C 语言字符串布吉路长度信息,需要遍历整个字符串时间复杂度为 O(n),C 字符串遍历时遇到 ‘\0’ 时结束。
SDS 中 len 保存这字符串的长度,用的时候直接读取,O(1) 时间复杂度。
SDS 被修改后,程序不仅会为 SDS 分配所需要的必须空间,还会分配额外的未使用空间。
分配规则如下:如果对 SDS 修改后,len 的长度小于 1M,那么程序将分配和 len 相同长度的未使用空间。举个例子,如果 len=10,重新分配后,buf 的实际长度会变为 10(已使用空间)+10(额外空间)+1(空字符)=21。如果对 SDS 修改后 len 长度大于 1M,那么程序将分配 1M 的未使用空间。
因为 SDS 的空间预分配策略, SDS 字符串在增长过程中不会频繁的进行空间分配。
通过这种分配策略,SDS 将连续增长N次字符串所需的内存重分配次数从必定N次降低为最多N次。
当对 SDS 进行缩短操作时,程序并不会回收多余的内存空间,而是使用 free 字段将这些字节数量记录下来不释放,后面如果需要 append 操作,则直接使用 free 中未使用的空间,减少了内存的分配。
字符串的拼接操作是使用十分频繁的,在C语言开发中使用char *strcat(char *dest,const char *src)方法将src字符串中的内容拼接到dest字符串的末尾。由于C字符串不记录自身的长度,所有strcat方法已经认为用户在执行此函数时已经为dest分配了足够多的内存,足以容纳src字符串中的所有内容,而一旦这个条件不成立就会产生缓冲区溢出,会把其他数据覆盖掉,非常危险。
而当SDS API需要对SDS进行修改时,API会先检查 SDS 的空间是否满足修改所需的要求,如果不满足,API会自动将SDS的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改SDS的空间大小,也不会出现缓冲区溢出问题。
在 Redis 中不仅可以存储 String 类型的数据,也可能存储一些二进制数据。
二进制数据并不是规则的字符串格式,其中会包含一些特殊的字符如 ‘\0’,在 C 中遇到 ‘\0’ 则表示字符串的结束,这限制了C字符串只能保存文本数据,而不能保存二进制数据。
而SDS使用len属性的值判断字符串是否结束,所以不会受’\0’的影响。
我们先来看一下源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | typedef struct dictEntry dictEntry; /* opaque */ typedef struct dict dict; typedef struct dictType { uint64_t (*hashFunction)(const void *key); void *(*keyDup)(dict *d, const void *key); void *(*valDup)(dict *d, const void *obj); int (*keyCompare)(dict *d, const void *key1, const void *key2); void (*keyDestructor)(dict *d, void *key); void (*valDestructor)(dict *d, void *obj); int (*expandAllowed)(size_t moreMem, double usedRatio); /* Flags */ /* The 'no_value' flag, if set, indicates that values are not used, i.e. the * dict is a set. When this flag is set, it's not possible to access the * value of a dictEntry and it's also impossible to use dictSetKey(). Entry * metadata can also not be used. */ unsigned int no_value:1; /* If no_value = 1 and all keys are odd (LSB=1), setting keys_are_odd = 1 * enables one more optimization: to store a key without an allocated * dictEntry. */ unsigned int keys_are_odd:1; /* TODO: Add a 'keys_are_even' flag and use a similar optimization if that * flag is set. */ /* Allow each dict and dictEntry to carry extra caller-defined metadata. The * extra memory is initialized to 0 when allocated. */ size_t (*dictEntryMetadataBytes)(dict *d); size_t (*dictMetadataBytes)(void); /* Optional callback called after an entry has been reallocated (due to * active defrag). Only called if the entry has metadata. */ void (*afterReplaceEntry)(dict *d, dictEntry *entry); } dictType; struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; /* Next entry in the same hash bucket. */ void *metadata[]; /* An arbitrary number of bytes (starting at a * pointer-aligned address) of size as returned * by dictType's dictEntryMetadataBytes(). */ }; typedef struct { void *key; dictEntry *next; } dictEntryNoValue; |
Redis 整体就是一个 哈希表来保存所有的键值对,无论数据类型是 5 种的任意一种。哈希表,本质就是一个数组,每个元素被叫做哈希桶,不管什么数据类型,每个桶里面的 entry 保存着实际具体值的指针。
整个数据库就是一个全局哈希表,而哈希表的时间复杂度是 O(1),只需要计算每个键的哈希值,便知道对应的哈希桶位置,定位桶里面的 entry 找到对应数据,这个也是 Redis 快的原因之一。
那 Hash 冲突怎么办?
当写入 Redis 的数据越来越多的时候,哈希冲突不可避免,会出现不同的 key 计算出一样的哈希值。
Redis 通过链式哈希解决冲突:也就是同一个桶里面的元素使用链表保存。但是当链表过长就会导致查找性能变差。
所以 Redis 为了追求快,使用了两个全局哈希表,用于 rehash 操作,增加现有的哈希桶数量,减少哈希冲突。
开始默认使用 hash 表 1 保存键值对数据,哈希表 2 此刻没有分配空间。当数据越来多触发 rehash 操作,则执行以下操作:
给 hash 表 2 分配更大的空间;
将 hash 表 1 的数据重新映射拷贝到 hash 表 2 中;
释放 hash 表 1 的空间。
值得注意的是,将 hash 表 1 的数据重新映射到 hash 表 2 的过程中并不是一次性的,这样会造成 Redis 阻塞,无法提供服务。
而是采用了渐进式 rehash,每次处理客户端请求的时候,先从 hash 表 1 中第一个索引开始,将这个位置的 所有数据拷贝到 hash 表 2 中,就这样将 rehash 分散到多次请求过程中,避免耗时阻塞。
当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis 就会使用整数集合作为集合键的底层实现。结构如下:
1 2 3 4 5 | typedef struct intset { uint32_t encoding; // 根据整数值的大小决定编码方式,编码方式优先级:Int64 > Int32 > Int16 uint32_t length; // 集合中元素个数 int8_t contents[]; // 保存元素的数组,这里保存为字节数组,根据编码方式进行顺序存取 } intset; |
contents 数组是整数集合的底层实现:需要注意的是这里contents的元素个数不等于length(因为当encoding == 64时,一个元素就会占用8个字节,以此类推),contents中的元素按照从小到大的顺序排列,不包含任何重复元素。
skiplist本质上也是一种查找结构,用于解决算法中的查找问题(Searching),即根据给定的key,快速查到它所在的位置(或者对应的value)。
跳表指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。
这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。
在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
跳跃表支持平均 O(logN)、最坏 O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
skiplist在Redis中的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | /* ZSETs use a specialized version of Skiplists */ typedef struct zskiplistNode { sds ele; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned long span; } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist; typedef struct zset { dict *dict; zskiplist *zsl; } zset; |
从源码中可知:
zskiplistNode backward字段是指向链表前一个节点的指针(前向指针)。节点只有1个前向指针,所以只有第1层链表是一个双向链表。
跳表也是Redis zset的一种底层数据结构。
为什么要设计 quicklist?
原有的ziplist存在两个问题,
1. 不能保存过多的元素,否则访问性能会下降
2. 不能保存过大的元素,否则容易导致内存重新分配,甚至引起连锁更新
特点
quicklist 的设计,其实是结合了链表和 listpack 各自的优势。简单来说,一个 quicklist 就是一个链表,而链表中的每个节点又是一个entry,每个entry中包含了对应对的listpack。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | typedef struct quicklistNode { struct quicklistNode *prev; struct quicklistNode *next; unsigned char *entry; size_t sz; /* entry size in bytes */ unsigned int count : 16; /* count of items in listpack */ unsigned int encoding : 2; /* RAW==1 or LZF==2 */ unsigned int container : 2; /* PLAIN==1 or PACKED==2 */ unsigned int recompress : 1; /* was this node previous compressed? */ unsigned int attempted_compress : 1; /* node can't compress; too small */ unsigned int dont_compress : 1; /* prevent compression of entry that will be used later */ unsigned int extra : 9; /* more bits to steal for future usage */ } quicklistNode; typedef struct quicklistLZF { size_t sz; /* LZF size in bytes*/ char compressed[]; } quicklistLZF; typedef struct quicklistBookmark { quicklistNode *node; char *name; } quicklistBookmark; typedef struct quicklist { quicklistNode *head; quicklistNode *tail; unsigned long count; /* total count of all entries in all listpacks */ unsigned long len; /* number of quicklistNodes */ signed int fill : QL_FILL_BITS; /* fill factor for individual nodes */ unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */ unsigned int bookmark_count: QL_BM_BITS; quicklistBookmark bookmarks[]; } quicklist; typedef struct quicklistIter { quicklist *quicklist; quicklistNode *current; unsigned char *zi; /* points to the current element */ long offset; /* offset in current listpack */ int direction; } quicklistIter; typedef struct quicklistEntry { const quicklist *quicklist; quicklistNode *node; unsigned char *zi; unsigned char *value; long long longval; size_t sz; int offset; } quicklistEntry; |
紧凑列表,用一块连续的内存空间来紧凑保存数据,同时使用多种编码方式,表示不同长度的数据(字符串、整数)。
在Redis中主要用于替代原本的linklist和ziplist。
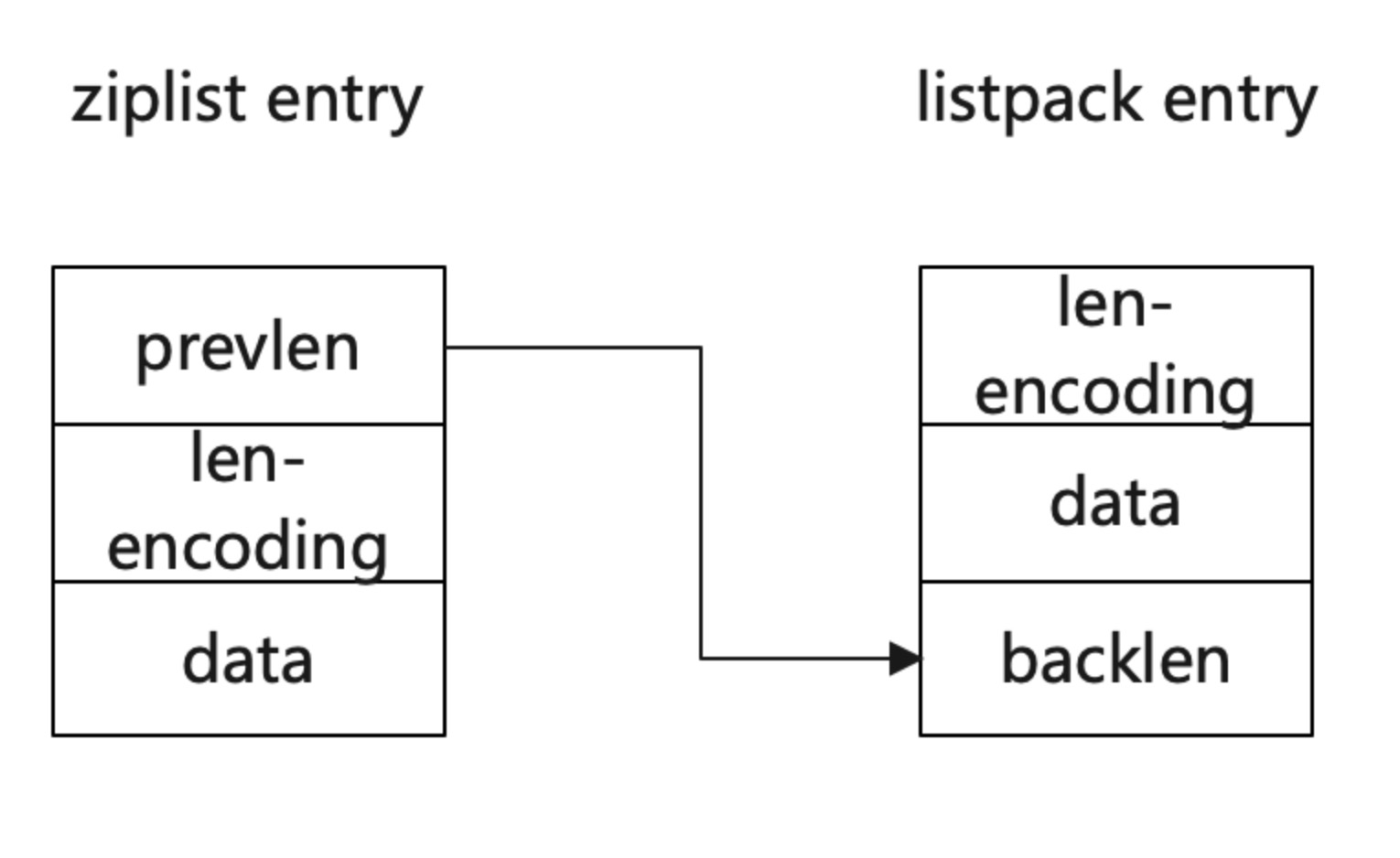
从以上结构中可以看到,listpack移除了prevlen,在data后新增了backlen,两者有着本质区别:
● 在ziplist中,prevlen代表前一个entry节点长度的偏移量;
● 在listpack中,backlen代表的是本entry节点的回朔起始地址长度的偏移量
Entry这样设计具有以下一些优势:
● 在遍历最后一个entry时可以通过lp+totallen快速定位到lp尾地址,然后使用backlen快速定位到last entry的起始地址;***并且可以将head中的last offset字段节省出来;
● 由于backlen仅代表了回朔本entry起始地址长度的偏移量,所以在增/删/改时,无需再关心前一个节点的长度,仅需要整体移动entry即可,所以不会涉及到内存的连锁更新;
stream 数据结构采用的是基数树包装的listpack(Encoded as a radix tree of listpacks),保证了消息队列数据存储的稳定和和可靠性,这里先不详细说明,后续写消息队列再详细讨论。
不是大家都说Redis是单线程的吗?怎么你这里还结合上多线程了?
首先,Redis的命令执行,数据操作确实是在同一个线程串行执行的,这也就是传统意义上的Redis是单线程的说法由来。
但是,对于 Redis 的持久化、集群数据同步、异步删除等都是其他线程执行;在Redis6.0以后,官方提供了多线程处理网络IO的选项,需要注意的是,Redis 多线程IO模型只用来处理网络读写请求,对于 Redis 的读写命令,依然是单线程处理。
为什么Redis不充分利用多核呢?
官方的说法是Redis在大多数时候性能瓶颈都不在CPU上,单核心就已经足够了;但随着数据结构的越来越复杂多样,官方也在努力推进Redis多线程化,比如6.0以后网络io的多线程化处理。
1. 不会因为线程创建导致的性能消耗;
2. 避免上下文切换引起的 CPU 消耗,没有多线程切换的开销;
3. 避免了线程之间的竞争问题,比如添加锁、释放锁、死锁等,不需要考虑各种锁问题。
4. 代码更清晰,处理逻辑简单。
1. 可以充分利用物理服务器多核心的优势,所以在Redis6.0以后充分利用了这一点,将网络io放在多线程进行处理。
2. io线程数量可配置,但一般不超过8个,根据官方说法,超过8个线程以后就没有什么太多的实际意义了。
在Linux中,默认情况下所有socket都是阻塞的,每一次读取调用都需要内核先准备好数据报文=>拷贝数据报文=>执行拷贝操作=>返回执行完成这样串行操作并返回结果。
对于网络IO来说,很多时候数据在一开始还没到达时(比如还没有收到一个完整的TCP包),系统内核就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。
当系统内核一直等到数据准备好了,它就会将数据从系统内核中拷贝到用户内存中,然后系统内核返回结果,用户进程才解除阻塞的状态,重新运行起来。所以,阻塞IO模型的特点就是在IO执行的两个阶段(等待数据和拷贝数据)都被阻塞了。
但是,我们可以通过设置socket使IO变为非阻塞状态,如果内核中的数据还没有准备好,那么它不会阻塞用户进程,而是立刻返回一个错误。
接下来就是用户进程循环执行相关操作,直到得到正确的状态码,所以,在非阻塞式IO中,用户进程其实需要不断地主动询问kernel数据是否准备好。非阻塞的接口相比阻塞型接口的显著差异在于被调用之后立即返回。
所以,在非阻塞式IO中,用户进程其实需要不断地主动询问kernel数据是否准备好。非阻塞的接口相比阻塞型接口的显著差异在于被调用之后立即返回。
多路IO复用,有时也称为事件驱动IO(Reactor设计模式)。它的基本原理就是有个函数会不断地轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
当用户进程调用了select,那么整个进程会被阻塞,而同时,内核会”监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从内核拷贝到用户进程。
这个模型和阻塞IO的模型其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而阻塞IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个连接。所以,如果系统的连接数不是很高的话,使用select/epoll的web server不一定比使用多线程的阻塞IO的web server性能更好,可能延迟还更大;select/epoll的优势并不是对单个连接能处理得更快,而是在于能处理更多的连接。
IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因为它使用了会阻塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO,而非真正的异步IO。
Redis的 I/O 多路复用程序的所有功能都是通过包装常见的select、epoll、evport、kqueue这些多路复用函数库来实现的。
因为Redis 为每个 I/O 多路复用函数库都实现了相同的API,所以I/O多路复用程序的底层实现是可以互换的。
Redis 在 I/O 多路复用程序的实现源码中用 #include 宏定义了相应的规则,程序会在编译时自动选择系统中性能最高的 I/O 多路复用函数库来作为 Redis 的 I/O 多路复用程序的底层实现
I/O 多路复用程序负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字。然后这些套接字的处理采用顺序队列来执行,保证事件不会错乱。
Redis通信协议RESP(REdis Serialization Protocol)是一种简单、快速、可读性强的协议,由Redis自身的需求所驱动,具有以下几个优点:
简单:RESP是一种基于文本的协议,易于实现和调试。它的语法简单明了,只包含一些基本的命令和数据类型,没有复杂的数据结构或语法。
快速:RESP使用简单的文本格式和紧凑的编码方式,数据传输量小,速度快。RESP还支持多条命令的批量执行,可以显著提高Redis的性能。
可读性强:RESP使用文本格式存储数据,使得数据易于读取和理解。RESP还支持一些特殊的数据类型,如Null、错误消息等,使得客户端能够更好地处理异常情况。
易于扩展:RESP支持多种数据类型,如字符串、整数、数组、错误消息等,这使得它易于扩展和适应不同的需求。
跨语言支持:RESP是一种独立于编程语言的协议,支持多种语言的实现,如Python、Java、PHP等,这使得Redis可以方便地与其他编程语言进行通信。
综上所述,Redis通信协议RESP具有简单、快速、可读性强、易于扩展和跨语言支持等优点,使得Redis能够更加高效、灵活地进行数据存储和通信。
Redis为什么这么快的原理总结:
1. 基于内存实现,基本都是在内存中进行高速存取操作,所以对CPU的消耗不大,速度极快;
2. 高效的数据结构(动态字符串(SDS)、跳表(skiplist)、哈希表(hashtable)、整数数组(intset)、快速列表(quicklist)、紧凑列表(listpack)、基数树(stream)等等);而且会根据不同的数据进行不同的数据编码选择;高效的数据结构和编码选择保证了数据的存取速度
3. 单线程结合多线程,保证了每个操作的原子性,也减少了线程的上下文切换和竞争;多线程解决网络io先关的瓶颈问题;
4. I/O多路复用;非阻塞I/O模型;用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,Redis 采用自己实现的事件分离器,效率比较高;
5. 高性能的自定义通讯协议RESP;简单、快速、可读性强、易于扩展和跨语言支持等优点,使得Redis能够更加高效、灵活地进行数据存储和通信;
6. 整个 Redis 就是一个全局 哈希表,他的时间复杂度是 O(1),而且为了防止哈希冲突导致链表过长,Redis 会执行 rehash 操作,扩充 哈希桶数量,减少哈希冲突。并且防止一次性 重新映射数据过大导致线程阻塞,采用 渐进式 rehash。巧妙的将一次性拷贝分摊到多次请求过程后总,避免阻塞。
程序猿老龚(龚杰洪)原创,版权所有,转载请注明出处.
{kind=link}
View Comments