GOLANG面试八股文-协程调度相关原理(GMP吟唱)
在 Golang 的并发编程中,强大的并发能力得益于其精妙的协程(Goroutine)调度机制。下面将详细介绍 Golang 的协程调度相关原理。
一、 为什么需要 Goroutine 调度器?
在高并发应用中,如果频繁创建和销毁操作系统线程,会带来巨大开销。
传统的线程池虽然预先保留一定数量的线程来消费任务队列,但在面对包含大量网络请求或系统调用(导致线程阻塞)的任务时,线程池的消费能力会大打折扣。
如果盲目增加线程数量,过多的线程去争抢 CPU 会引发频繁的上下文切换(Context Switch),反而成为系统性能瓶颈。
Go 提供了一种机制:在用户态自己实现调度。这样上下文切换更轻量(无需进入内核态),从而达到了“线程数少,但并发数极高”的效果,负责这套调度的就是 Go 调度器(GMP 模型)。
二、 GMP 模型的核心概念
Go 的调度机制建立在三个核心角色之上:
1. G (Goroutine)
即 Go 协程。代码中使用 `go` 关键字就会创建或复用一个 G 数据结构,包含了执行该协程所需的栈、指令指针等上下文信息。
2. M (Machine)
即代表由操作系统调度的内核工作线程。数量通常略大于 P 的个数(因为当 G 发生系统调用阻塞 M 时,调度器会唤醒或创建更多 M),G 只有依附在 M 上才能被执行。
3. P (Processor)
即逻辑处理器,包含运行 Goroutine 相关的资源。M 必须获取(持有)P 才可以运行 G。每个 P 维护着一个本地域的 G 队列。
程序启动时,P 的个数默认等于机器的 CPU 逻辑核数(可通过 `runtime.GOMAXPROCS()` 配置)。
其核心关系为:M 必须绑定 P 才能工作,P 控制着本地队列中众多 G 的执行权。除此之外,调度器还维护着一个“全局队列(Global Queue)”。
三、 Goroutine 调度机制与策略(面试官喜欢问的八股文)
调度器在运行时的平衡艺术,主要体现在以下三种核心策略上:
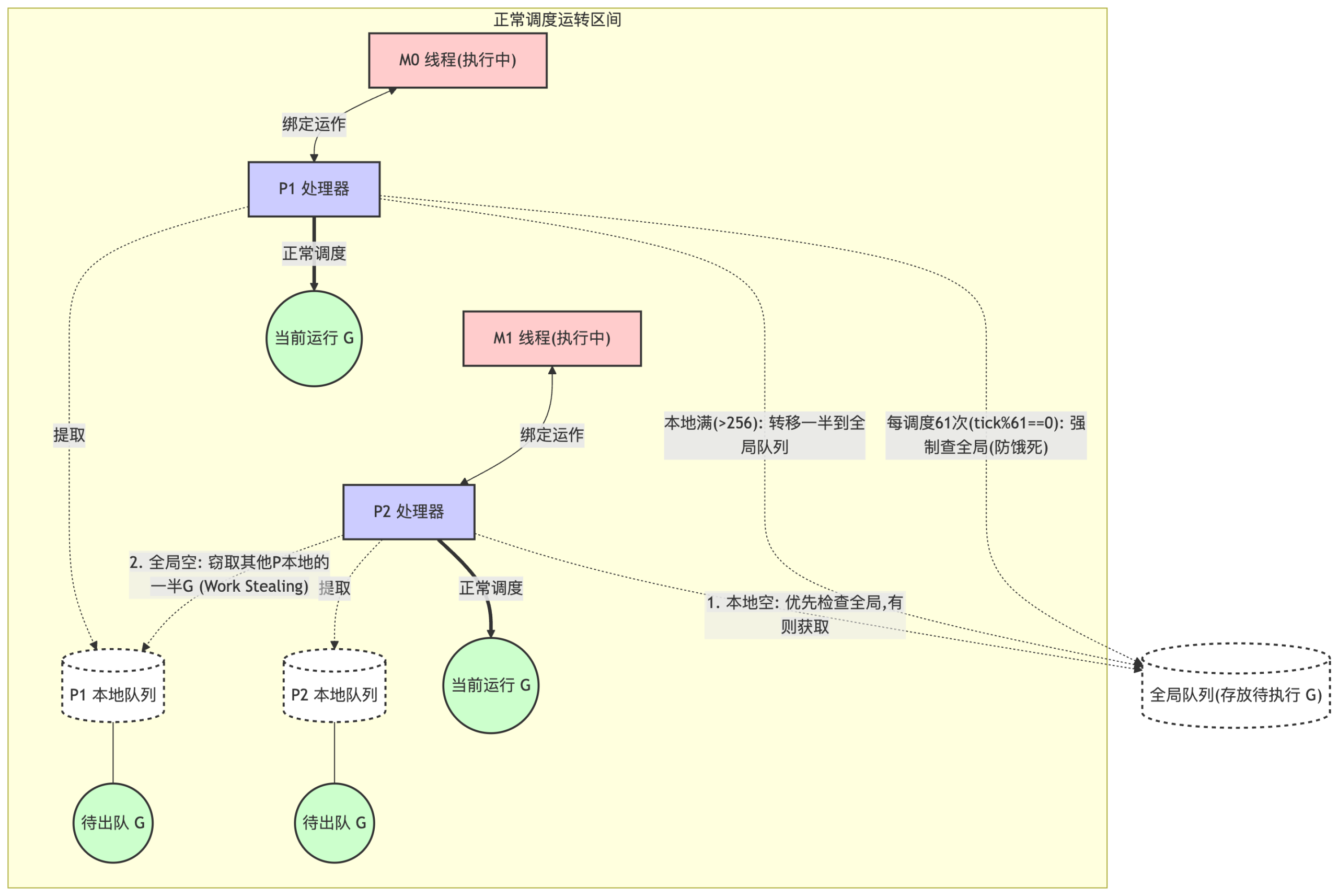
1. 队列轮转 (Round-Robin & Starvation Prevention)
P 周期性地将它本地队列里的 G 调度到绑定的 M 中执行,每个 G 都会被分配一小段时间片。一旦执行时间到了或者主动发起网络 IO(被 netpoller 挂起),G 的上下文会被保存,退回到队列末尾(或者其他队列)。
为了防止“全局队列”里的 G 被饿死,P 在调度时不仅会从本地队列拿 G,每隔一定周期(比如每 61 次调度)也会强制去查看全局队列中是否有待运行的 G,并将其调度到 M。
2. 工作量窃取 (Work Stealing)
如果并发度极度不平衡,导致某个 P 的本地队列空了,且全局队列里也没有待执行的 G,这个饥饿的 P 并不会闲着。它会尝试从其他 P 的本地队列里“偷取(Steal)”一部分 G 过来(一般是偷一半)。这种机制保证了在繁忙系统中,各个 CPU 核的负载被尽可能平均分摊,最大化资源利用率。
正常情况下的执行机制如图所示:
3. 系统调用处理 (System Call) 与 Handoff 机制
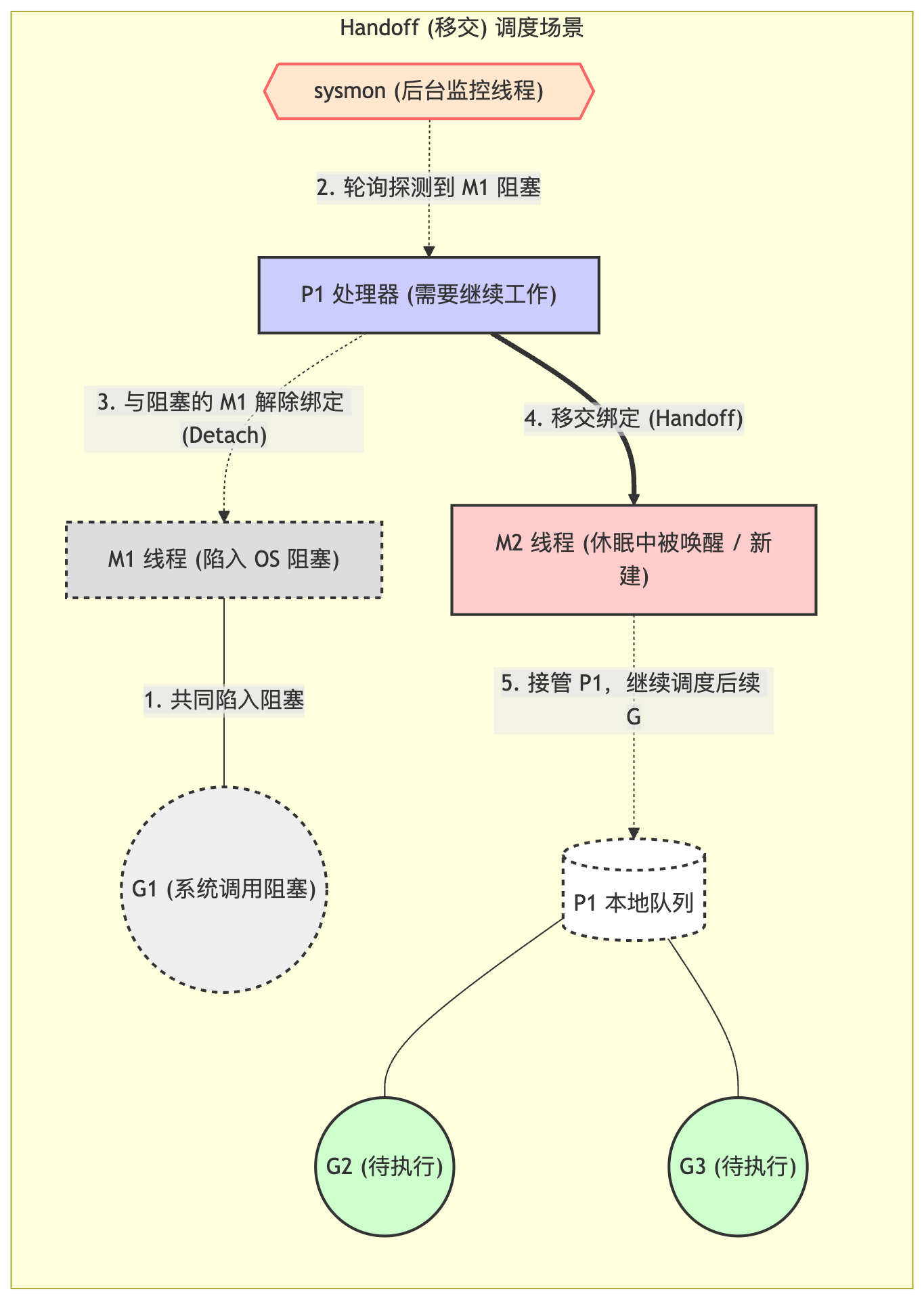
当 M0 正在执行某个 G0 时,如果 G0 发起了阻塞的系统调用,M0 也就跟着阻塞了。
此时,为了不浪费 P 的计算能力,M0 会主动释放掉它持有的 P,这就是所谓的 Handoff (移交) 机制。调度器会去寻找另一个空闲的 M1(不管是缓存池里唤醒的还是新建的)来接管这个 P,进而继续执行 P 本地队列中剩下的 G,保证 P 不闲置,CPU 资源得到充分利用。
当 G0 的系统调用结束后,M0 会脱离阻塞状态,并尝试重新获取一个 P 继续执行 G0:
– 如果能找到空闲的 P,则绑定并继续运行。
– 如果找不到空闲的 P,M0 就会把 G0 扔进全局队列等待其他 P 去捡起,然后 M0 自己乖乖进入休眠(放回缓存池)。
发生handoff时的执行机制如图所示:
四、 结合 Go 最新实现的演进补充
《GO专家编程》讲述了上述经典的 1.9.2 时期的 GMP 设计,但随着版本迭代,Go 调度器也解决了一些历史难题:
1. 抢占式调度 (Preemptive Scheduling) 的进化
极早期的 Go 没有抢占式调度,一个死循环的 G 会霸占整个 P 导致其他协程饿死。
Go 1.14 后引入了基于信号(SIGURG)的异步抢占调度。后台系统的 `sysmon` 线程(不依赖于 P)以极其微小的周期持续监控,如果发现某个 G 执行时间过长(超过 10ms),就会向该 M 发送操作系统信号,强行中断它并切走 G,真正实现了无死角的抢占。
2. 网络轮询器 (NetPoller) 的结合
现代 Go 程序大部分阻塞都是网络 I/O,而不是纯系统调用。当 G 发起网络传输被阻塞时,它并不会霸占住操作系统的 M。相反,调度器会把该 G 丢给 NetPoller(利用底层的 epoll 等机制),原来那个 M 就可以继续愉快地执行其他 G 了。当网络数据响应时,NetPoller 再将该 G 重新唤醒并送入可运行队列。这极大地减少了 M 的创建开销。
五、 GOMAXPROCS 的设置与影响
默认情况下,`GOMAXPROCS` 会被设置为 CPU 核心数,因为这样减少了系统级线程互相争用的消耗。
但在某些极端特殊的场景(如早期的 CGO 密集型或大量阻塞式的磁盘 I/O 但没有用到 netpoller 优化的场景),线程由于底层阻塞会导致切换延迟,此时适当调大 `GOMAXPROCS` 有助于提供足量的 P 被新的 M 接管从而利用 CPU。但在 99% 的现代开发业务里,保留默认值(与核心数 1:1)依然是性能最高的最优解。
六、 常被问到的问题
为什么不直接让M从全局队列拿G执行,要搞一个P出来?
早期Go的调度器(Go 1.0)就是这么干的——没有P,所有G放在一个全局队列里,M从全局队列拿任务,用一把大锁保护。结果在多核机器上性能很差,锁竞争太严重。
P的作用是给每个线程一个本地队列, M优先从绑定的P的本地队列拿G,不需要加锁。本地队列空了再去全局队列或者偷别的P的任务(work-stealing)。
本地队列最多放256个G。超过256个的进全局队列。M从全局队列拿任务的频率也有讲究——每调度61次就检查一次全局队列,防止全局队列里的G饿死。
P的数量默认等于CPU核数(`GOMAXPROCS`),M的数量理论上没有上限(默认最多10000个),但活跃的M数量受P限制——没有空闲的P,M就拿不到任务,只能阻塞等着。
为什么执行系统调用的goroutine或者卡住的goroutine能被调走?
这个问题其实涉及两种情况,分别是执行系统调用阻塞Goroutine陷入死循环或密集计算。
情况一:Goroutine 执行系统调用 (Syscall) 阻塞
此时其实并不是 G 被调走了,而是 P 被调走了。
当 Goroutine 需要读写文件、网络 I/O 或其他系统调用时,底层的 OS 线程(M)是真真实实会被操作系统阻塞的。Go 调度器没有魔法,无法让被 OS 阻塞的线程继续跑代码。它的策略是“金蝉脱壳”:
主动报备 (entersyscall): 当 G 准备执行系统调用时,它会调用运行时的 entersyscall 函数。这会将 G 的状态标记为 _Gsyscall,并主动切断当前 M 和 P 之间的强绑定关系(但 M 还会保留指向 P 的指针,以防 syscall 瞬间完成)。
sysmon 介入 (Handoff 机制): 后台的 sysmon 监控线程每隔很短的时间(最多 10ms)就会轮询一次。如果它发现某个 P 处于 syscall 状态的时间过长,它就会毫不犹豫地将这个 P 剥离 (Retake),分配给其他空闲的 M(或新建 M)去执行 P 本地队列里的其他 G。
调用结束 (exitsyscall): 当那个阻塞的系统调用终于返回时,原本的 M 醒来,想要继续执行剩下的 Go 代码。此时它会尝试:
优先找回原来的 P(如果还没被拿走)。
如果原来的 P 没了,尝试从全局空闲 P 队列里随便偷一个。
如果实在找不到 P: M 会把当前这个 G 扔进全局队列(Global Queue),然后自己乖乖进入休眠状态,等待下次被唤醒。
对于系统调用,Go 采用的是“抛弃阻塞线程,转移执行环境(P)”的策略。
情况二:Goroutine 陷入死循环或密集计算 (CPU 卡死)
如果一个 G 只是在执行 for { doSomethingNoneSyscall() },没有发生系统调用,也没有主动让出,它是怎么被调走的呢?这依靠的是 抢占式调度。
Go 1.14 之后,引入了真正的异步抢占机制:
sysmon 盯着你: 还是那个勤奋的 sysmon 线程。它除了监控系统调用,还会监控每个 P 的运行时间。如果发现一个 G 连续运行超过了 10ms (时间片)。
发送 UNIX 信号: sysmon 判定这个 G 占用了太多时间,它会向运行这个 G 的 M (底层操作系统线程) 发送一个底层的信号——通常是 SIGURG 信号。
强制中断并保存现场: M 收到 SIGURG 信号后,会被操作系统强制中断当前的执行流,跳转到 Go 运行时注册的信号处理函数中。
注入异步抢占调用: 信号处理函数会在当前 G 的执行上下文中“动手脚”,强行修改 G 的寄存器(如 PC 指针),使得 G 从信号处理函数返回时,不直接回到死循环,而是跳转到一个叫 asyncPreempt 的函数。
乖乖交出控制权: asyncPreempt 函数会将 G 当前的状态(寄存器、栈)保存起来,将其状态修改为 _Runnable,扔回全局队列,然后让当前的 M 和 P 去执行其他的 G。
对于死循环或者其他需要大量计算的任务,Go借助操作系统层面的信号 (Signal) 机制,实现了硬核的异步打断和抢占。
追问:当 G 尝试向一个满载的 Channel 发送数据而被阻塞时,调度器又是如何处理的?这与上面两种情况又有微妙的不同?
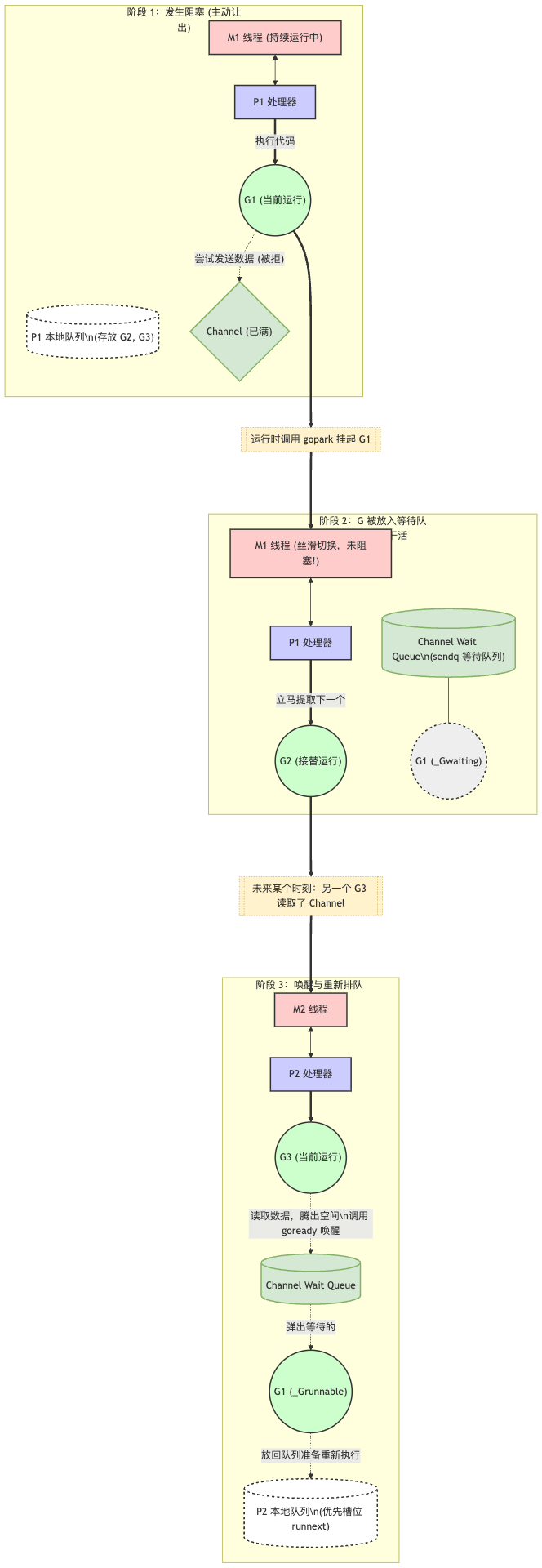
与前两种情况(操作系统级别的卡住、死循环的 CPU 卡死)完全不同,当 Goroutine 在 Channel 上阻塞时,底层的操作系统线程 (M) 根本不会被阻塞! 这一切都是在 Go 运行时(Runtime)的用户态悄悄完成的。为了直观展示,请看下面这张“Channel 阻塞与唤醒调度图”:
核心机制:gopark 与 goready
当 Goroutine 尝试向满的 Channel 写入,或从空的 Channel 读取时,它经历的是一次“主动休眠与被动唤醒”的过程:
1. 挂起 (Park):
当 G1 发现 Channel 满了,它会调用 Go 运行时的底层函数 gopark。
gopark 会做几件事:将 G1 的状态从运行中 (_Grunning) 改为等待中 (_Gwaiting);将 G1 从 P1 上剥离;将 G1 的指针塞进这个 Channel 内部自带的等待队列(发送方队列 sendq 或 接收方队列 recvq)中。
最关键的一点: 底层的 M1 线程压根没有向操作系统发起任何阻塞调用。它只是把 G1 放到了别的地方,然后立刻转身去 P1 的本地队列里拿下一个 G2 继续执行。因此,线程资源 0 浪费。
2. 沉睡的 G1:
此时的 G1 就像一个被冻结的数据结构,安静地躺在 Channel 的队列里,不消耗任何 CPU 资源。
3. 唤醒 (Ready):
过了不知道多久,程序中另一个协程 G3(可能在当前的 P 上,也可能在其他线程的 P 上)执行了读取这个 Channel 的操作。
G3 拿走了一个数据,Channel 腾出了一个空位。
G3 在完成读取后,会顺手检查一下 Channel 的等待队列。它发现了沉睡的 G1,于是调用运行时的 goready 函数。
goready 会将 G1 的状态从等待 (_Gwaiting) 改为可运行 (_Grunnable),并将其放入某个 P 的本地队列中。为了让刚被唤醒的协程尽快得到执行,通常会直接把它塞进 P 的 runnext(下一个立即执行的槽位)里。
随后,当某个 M 调度到 G1 时,G1 就会从上次卡住的 Channel 发送代码处继续往下执行,仿佛一切都没发生过。
终极总结:Go 调度器的“三板斧”
| 卡住的原因 | 发生层级 | 底层 OS 线程 (M) 的状态 | 调度器的应对策略 (黑魔法) |
| 系统调用 (Syscall) (读写文件、CGO等) | 操作系统 OS 级别 | 真阻塞。随 G 一起陷入内核态挂起。 | Handoff (移交):sysmon 把 P 剥离,分配给新的 M 继续干活。原 M 和 G 在后台傻等。 |
| 死循环 / 密集计算 | 纯 CPU 计算级别 | 一直跑。被死循环霸占。 | 异步抢占:sysmon 计时 10ms,发送 SIGURG 信号强行打断,把 G 踢回全局队列。 |
| Channel / 网络 IO / 锁 | Go 运行时 (Runtime) 级别 | 不阻塞。立刻去执行下一个 G。 | gopark / goready:把 G 扔进特定的等待队列(如 Channel 内部队列,网络 epoll 队列),等条件满足时由其他 G 唤醒。 |