MYSQL面试八股文-索引优化之全文索引(解决文本搜索问题)
背景:为什么要有全文索引
在当我们进行模糊查询的时候,一般都是使用 like 关键字来实现,在数据量小的情况下效率确实可以。
有的人会说了,数据量大的时候我加索引啊。确实可以加索引,而且 like condition% 是可以使用到索引的,但是当你要 like %condition% 或 %condition 这样使用就会导致索引无效。
而且,如果我们想要同时搜索多个字段呢,例如同时搜索用户名和用户个性签名里面要包含 “约”关键字,like 查询显然是办不到的。
这时为了满足需求,同时能快速的进行查询,我们可以引入Elasticsearch或者使用MySQL自带的全文索引。本文只介绍全文索引的原理和使用。
底层算法实现
MySQL的全文索引底层算法主要使用了倒排索引(Inverted Index)和自然语言处理技术。
1. 倒排索引(Inverted Index):
倒排索引是一种将词条映射到文档的索引结构。它将文档中的每个词条(通常是单词)作为关键词,建立起关键词到包含该关键词的文档的映射关系。
对于全文索引,MySQL使用倒排索引来快速查找包含特定关键词的文档或记录。倒排索引中的每个关键词都会存储一份包含该关键词的文档列表,以及每个文档中关键词出现的位置信息。
倒排索引通过建立词汇表(Vocabulary)来存储所有出现过的关键词,并为每个关键词维护一个指向对应文档列表的指针。
自然语言处理技术:
MySQL使用自然语言处理技术来处理全文索引的查询和匹配。这包括对搜索词进行分词(Tokenization)和词干提取(Stemming)等处理。
分词是将查询词或文本分解为一个个独立的词条的过程。在全文索引中,MySQL会将查询词进行分词,并与倒排索引中的关键词进行匹配。
词干提取是将单词还原为其原始词干的过程。例如,将”running”、”runs”和”ran”等不同形式的词还原为其共同的词干”run”,以便更好地进行匹配。
综合运用倒排索引和自然语言处理技术,MySQL的全文索引能够高效地进行文本搜索和匹配,提供全文检索功能。
通过使用合适的算法和数据结构,MySQL能够快速地定位包含特定关键词的文档或记录,支持各种全文搜索操作,并提供相应的查询性能。
使用实战
首先有请出我们的老演员,社交产品用户表,630万用户。
需求: 找出用户名,个性签名,问候语中含有“dating”字样的用户。
创建全文索引
正常创建
我们先在用户名`realname`字段上创建一个全文索引:
1 2 | ALTER TABLE 'july_user' ADD FULLTEXT INDEX 'id_fulltext_realname' ('realname') WITH PARSER 'ngram' COMMENT '用户名全文索引'; |
注意,这里的 `WITH PARSER ‘ngram’` 是显式的声明使用分词插件ngram,用以适配中日韩等多种语言的分词查询。
上面我们实现了单个字段的全文索引创建,但是,我们上面不是说要同时查找用户名,用户签名和问候语吗?那么我们来改一改。
1 2 | ALTER TABLE `july_user` ADD FULLTEXT INDEX `idx_fulltext_user_related`(`greeting_words`, `signature`, `realname`) WITH PARSER `ngram` COMMENT '用户名,用户签名,打招呼语全文索引'; |
你以为这么简单就完成了吗?to young to simple,此时你大概率会遇到个错误:
1 | Error Code: 1062. Duplicate entry '0' FOR KEY 'idx_fulltext_user_related' |
在表原始数据量较大的场景下几乎必现这个bug。那,怎么解决呢?
解决或者说绕过 Error Code: 1062. Duplicate entry ” for key ” bug
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | -- 从原来的表结构创建一张结构完全一致的新表 CREATE TABLE `july_user_slave` LIKE `july_user`; -- 给新表添加我们需要的索引 ALTER TABLE `july_user_slave` ADD INDEX `index_online_date`(`online_date`) USING BTREE COMMENT '最后在线时间索引', ADD FULLTEXT INDEX `index_fulltext_user_info`(`signature`, `realname`, `words`) WITH PARSER `ngram` COMMENT '用户信息全文索引'; -- 从旧表把数据全量复制到新表 INSERT INTO `july_user_slave` ( user_id, ………… video_message_mins ) SELECT user_id, ………… video_message_mins FROM july_user; -- 将旧表命名为july_user_bak ALTER TABLE july_user RENAME TO july_user_bak; -- 将新表july_user_slave重命名为july_user ALTER TABLE july_user_slave RENAME TO july_user; |
整体的思路跟大表加字段,加索引的思路是一样的,都是新建一张表,然后执行我们想要的加字段或者加索引操作,然后将数据复制过来,再将表进行重命名。
使用全文索引
查询语法和搜索模式
MySQL的全文索引支持多种搜索模式,用于在文本数据中进行灵活的全文搜索。以下是几种常见的MySQL全文索引搜索模式:
自然语言搜索模式(NATURAL LANGUAGE MODE):
自然语言搜索模式使用自然语言处理技术来解析查询词,并按相关性对结果进行排序。
在自然语言搜索模式下,MySQL会对查询词进行分词和词干提取,并将关键词与文档进行匹配。
MySQL会根据关键词的重要性和出现频率来计算文档的相关性,并将相关性高的文档排在前面。
可以使用MATCH() AGAINST(xxx IN NATURAL LANGUAGE MODE)语句进行自然语言搜索,例如:
1 | SELECT * FROM 表名 WHERE MATCH(列名) AGAINST('查询词' IN NATURAL LANGUAGE MODE); |
布尔搜索模式(BOOLEAN MODE):
布尔搜索模式允许使用布尔运算符(AND、OR、NOT)和通配符(+、-、*)来组合和限制搜索条件。
在布尔搜索模式下,可以使用布尔运算符来组合多个查询词,并使用通配符进行模糊匹配和排除特定词汇。
可以使用MATCH() AGAINST(xxx IN BOOLEAN MODE)语句进行布尔搜索,例如:
1 | SELECT * FROM 表名 WHERE MATCH(列名) AGAINST('词1 +词2 -词3' IN BOOLEAN MODE); |
短语搜索模式(PHRASE MODE):
短语搜索模式用于匹配特定的短语或词组,要求查询词按照指定的顺序和位置连续出现在文本中。
在短语搜索模式下,可以使用双引号将查询词组括起来,MySQL会按照顺序和位置进行匹配。
可以使用MATCH() AGAINST(xxx IN BOOLEAN MODE)语句进行短语搜索,例如:
1 | SELECT * FROM 表名 WHERE MATCH(列名) AGAINST('"查询词组"' IN BOOLEAN MODE); |
通过使用不同的搜索模式,可以根据具体的需求进行全文搜索操作,提供更精确和灵活的搜索结果。
在使用全文索引进行搜索时,需要根据数据特点和业务需求选择合适的搜索模式,并合理构建查询语句以获得期望的搜索结果。
实战查询
找出用户名,个性签名,问候语中含有“dating”字样的用户,
我们先用explain查看是否走了索引
1 2 3 4 5 6 7 8 9 10 11 | EXPLAIN SELECT user_id, realname, signature, words FROM july_user WHERE MATCH ( `signature`, `realname`, `words` ) AGAINST ( 'dating' IN BOOLEAN MODE ) LIMIT 20; |
从结果可以看到,成功的走到了全文索引:

查询结果
1 2 3 4 5 6 7 8 9 10 | SELECT user_id, realname, signature, words FROM july_user WHERE MATCH ( `signature`, `realname`, `words` ) AGAINST ( 'dating' IN BOOLEAN MODE ) LIMIT 20; |
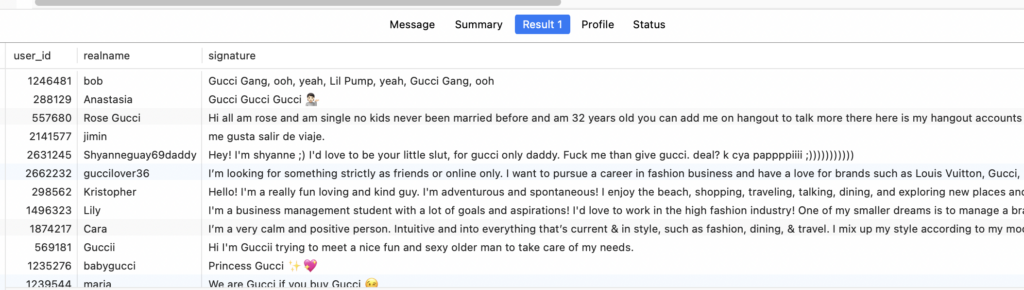
从上面的查询分析和结果来看,能够走到全文索引并得到正确的结果,查询效率也还相对较快,基本都能在1秒内得到结果。
中文查询问题
我们来看两句SQL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SELECT user_id, realname, signature, words FROM july_user WHERE MATCH ( `signature`, `realname`, `words` ) AGAINST ( '约' IN BOOLEAN MODE ) LIMIT 20; SELECT realname FROM july_user WHERE realname LIKE '%约%'; |
从查询结果可以看出,明明用户名就已经包含了中文“约”字,但通过全文索引进行查询反而没有结果。


这里的主要原因是我们使用了ngram分词插件,用到一个全局参数ngram_token_size,这个参数的默认值为2,表示分词最短长度为2,也就意味着必须要有两个字符才能查询出结果。
1 2 3 4 5 6 7 | mysql> SHOW global VARIABLES LIKE '%ngram%'; +------------------+-------+ | Variable_name | VALUE | +------------------+-------+ | ngram_token_size | 2 | +------------------+-------+ 1 ROW IN SET (0.00 sec) |
且ngram_token_size在启动后为只读参数,所以我们需要在MySQL启动之前在配置文件中修改或使用参数进行启动。
1 2 3 4 5 6 | Startup string: mysqld --ngram_token_size=1 Configuration file: [mysqld] ngram_token_size=1 |
在修改完上面的参数之后,我们还需要执行以下SQL来刷新索引。
1 | OPTIMIZE TABLE july_user; |
刷新之后的查询结果:
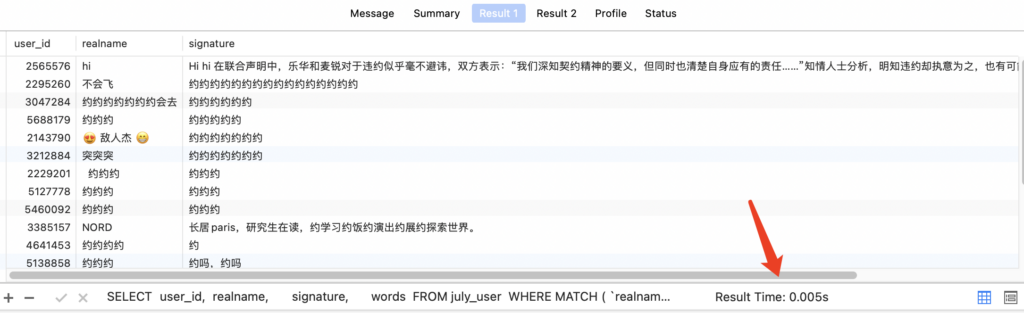
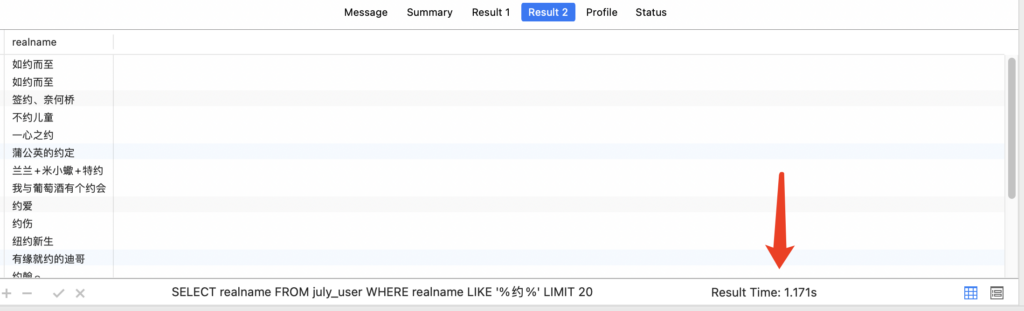
从上面的结果可知,同样是查询20条数据,like不走索引对比全文索引的查询时间慢了接近1000倍,差距巨大,由此可见,全文索引确实可以提高查询速度。
总结
1. 在多字段文本查询的环境下,like无法满足对应需求并快速查询,此时可以用到全文索引提升查询速度。
2. MySQL的全文索引底层算法主要使用了倒排索引(Inverted Index)和自然语言处理技术。
3. 全文索引可以支持多字段,精确查询,模糊查询以及自然语言分词。
4. 使用ngram进行分词查询时,需要注意设置ngram_token_size=1才能进行单个字的查询。
程序猿老龚(龚杰洪)原创,版权所有,转载请注明出处.